|
1
2
3
4
5
6
7
8
9
|
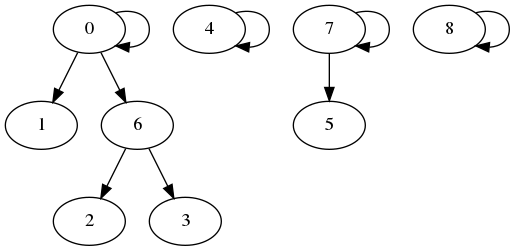
Au début :Indices : 0 1 2 3 4 5 6 7 8Tableau : 0 1 2 3 4 5 6 7 8Hauteur : 1 1 1 1 1 1 1 1 1Après les opérations :Indices : 0 1 2 3 4 5 6 7 8Tableau : 0 0 6 6 4 7 0 7 8Hauteur : 3 0 0 0 1 0 0 2 1 |
Au début :
Indices : 0 1 2 3 4 5 6 7 8
Tableau : 0 1 2 3 4 5 6 7 8
Hauteur : 1 1 1 1 1 1 1 1 1
Après les opérations :
Indices : 0 1 2 3 4 5 6 7 8
Tableau : 0 0 6 6 4 7 0 7 8
Hauteur : 3 0 0 0 1 0 0 2 1
Implémentation par marqueurs
Premier type d'implémentation : avec un tableau. Exemple ci-contre avec les opérations :
|
1
2
3
4
5
|
fusion(parttition, hauteur, 0, 1);fusion(parttition, hauteur, 6, 3);fusion(parttition, hauteur, 6, 2);fusion(parttition, hauteur, 0, 3);fusion(parttition, hauteur, 7, 5); |
fusion(parttition, hauteur, 0, 1); fusion(parttition, hauteur, 6, 3); fusion(parttition, hauteur, 6, 2); fusion(parttition, hauteur, 0, 3); fusion(parttition, hauteur, 7, 5);
Implémentation arborescente
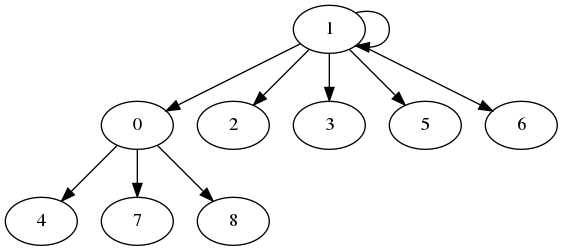
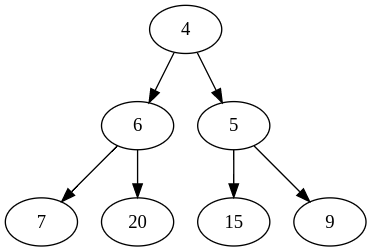
Ici, on reprend les mêmes données que précédemment, et chaque arbre représente une classe de la partition. Pour rappel, au début nous avons :

On obtient ce résultat :
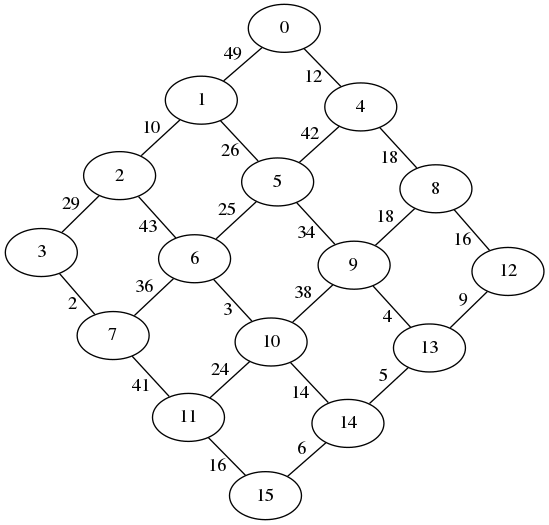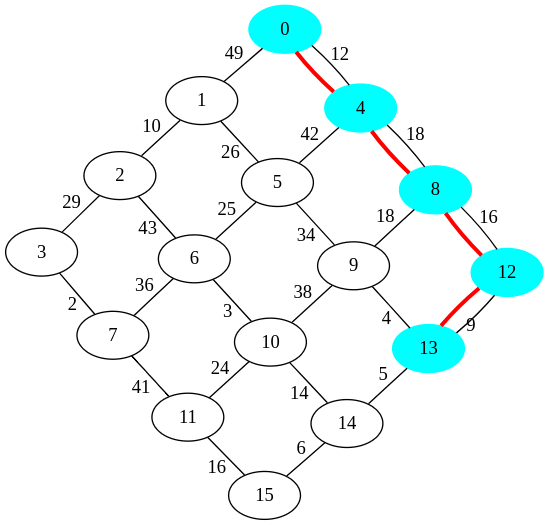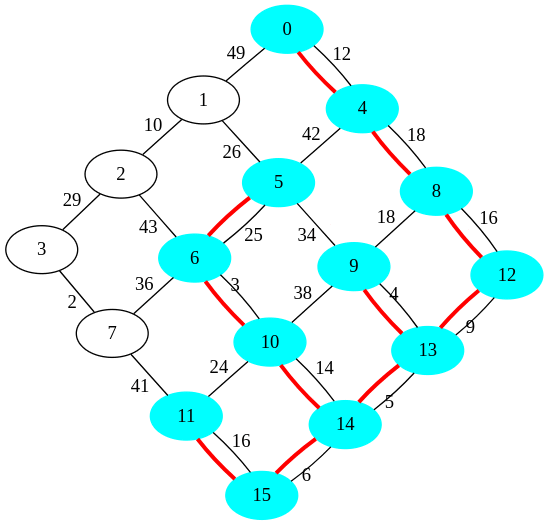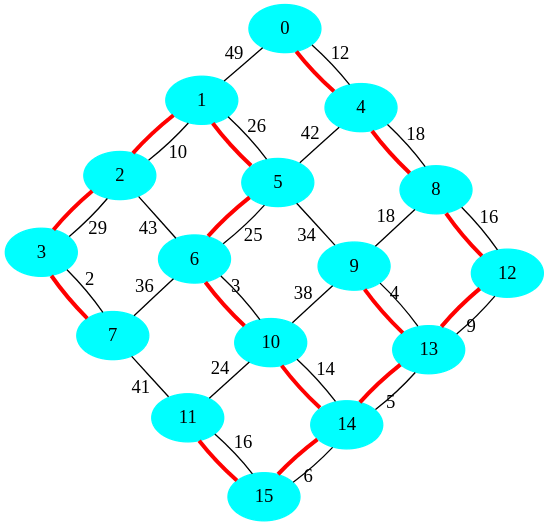
Graphe généré grâce à la matrice d'adjacence :
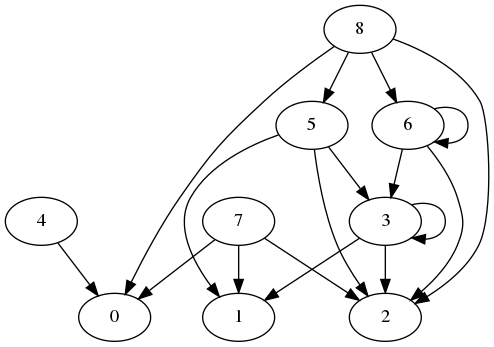
Composantes connexes de graphes aléatoires
Dans un premier temps, on génère de manière aléatoire une matrice d'adjacence. Cette matrice permet de générer le graphe ci-contre.
Ensuite, les composantes connexes sont extraites et on obtient le résultat ci-dessous :