Introduction à Git
Table des matières
- 1. Gestion de version
- 2. Git
- 3. Découverte pas à pas
- 3.1. Sur l'ordinateur de travail
- 3.1.1. Paramétrage de Git en local
- 3.1.2. Démarrer un projet sur l'ordinateur local
- 3.1.3. Créer un premier fichier
- 3.1.4. Ajout d'un fichier
- 3.1.5. Premiers commits
- 3.1.6. Les branches
- 3.1.7. Se promener dans le passé
- 3.1.8. Annuler un commit
- 3.1.9. Retourner dans un état précédent
- 3.1.10. TODO Choisir de récupérer uniquement certains éléments de vieux commits
- 3.1.11. TODO Découper un commit en plusieurs commits
- 3.1.12. Nettoyer, réorganiser ses commits
- 3.1.13. Aide pour récupérer
- 3.2. Sur le site de GitLab
- 3.1. Sur l'ordinateur de travail
- 4. Et l'ami emacs ?
- 5. Webographie

Figure 1 : Git
1 Gestion de version
1.1 Problématique
Lorsque l'on travaille sur un projet (gestion des flux chez PSA, TP à rendre, recettes de cuisine, …), on procède souvent de façon non totalement linéaire. On fait des essais, certains portent leurs fruits, d'autres non. Une bonne gestion a donc longtemps consisté à créer des répertoires de sauvegarde, à faire fréquemment des copies, à bien détailler la liste des changements entre les versions dans des fichiers textes et à bien uniformiser les fichiers afin de pouvoir faire des recherches… Beaucoup de travail d'archivage, même pour des projets assez petits, et titannesque pour de projets plus imposants.
A cela se rajoutent les difficultés engendrées par le travail à plusieurs. Par exemple si Alice et Bob désirent travailler tous les deux sur le même fichier :
- Sans rien de spécial
- Alice et Bob chargent le fichier "ztt42.c" ;
- Alice modifie une fonction du code, le redépose sous le même nom ;
- Bob modifie une fonction du code, le redépose sous le même nom -> seul le dernier dépôt est conservé, Alice aurait mieux fait de cultiver son jardin.
- avec un cadenas
- Alice met un cadenas sur le fichier pour dire qu'elle prend en main le fichier,
- Bob aurait bien aimé travailler dessus, mais non, il ne peut pas pour l'instant, il y a un cadenas ;
- Alice dépose la nouvelle version du fichier qu'elle a modifié (assez longtemps après, elle ne peut pas remettre une version qui ne fonctionne pas correctement, sinon les autres ne pourront pas travailler) et enlève le cadenas ;
- Bob met un cadenas et charge le fichier, il veut essayer différentes pistes, il gère ses différents essais, il y a des choses intéressantes, mais là, il n'a plus le temps, il rend le fichier…
C'est propre, pas de mélange, mais d'un confort très limité :
- on ne peut pas accéder aux fichiers lorsque quelqu'un d'autre les manipule,
- on doit gérer les versions soi-même ;
- le partage est compliqué.
- Avec un coordinateur
- Alice et Bob chargent le fichier "ztt42.c" ;
- Alice modifie une fonction du code, le redépose sous un nouveau nom ;
- Bob modifie une portion du code, le redépose sous un nouveau nom ;
- Charlie se met au travail et réalise la fusion :
- Si les deux modifications portent sur des parties indépendantes, il recopie les deux modifications ;
- Si les parties de code impliquées sont les mêmes, il réfléchit pour savoir comment s'en sortir, et si nécessaire renvoie à Alice et Bob le fichier afin qu'ils fassent les modifications eux-mêmes… Pas de miracle, malheureusement.
1.1.1 Bilan
En résumé les points qui semblent devoir être améliorés sont :
- accès concurrent en lecture et écriture sur des fichiers afin que chacun puisse apporter ses modifications ;
- automatisation des fusions lorsqu'elles ne créent pas de conflit
- gestion des droits de chacun des utilisateurs ;
- automatisation de l'archivage, avec possibilités de :
- maîtrise du passé du développement ;
- retour arrière sur des versions précédentes ;
- fusion de différentes versions.
- gestions en parallèle de différentes version du logiciel (la version commercialisée, la version en R&D, …)
Ce sont ces points sur lesquels les logiciels de gestion de version fournissent une aide.
1.1.2 Remarque pratique
Il est intéressant de noter que la gestion de version peut s'utiliser aussi bien pour des projets au sens usuel, que pour conserver des données. Ainsi, on peut l'utiliser pour conserver la configuration de son système (en particulier sa configuration d'emacs), des cours, des données personnelles, …
Dans ces logiciels, la sauvegarde est généralement incrémentale, ce qui signifie que seules les données modifiées sont réellement sauvegardées. On peut donc les utiliser pour aisément partager des informations entre différents ordinateurs (par exemple seul le travail de la journée est à charger lorsqu'on passe du bureau à la maison), avec toute la puissance de la gestion de version (retrouver une donnée perdue, …).
1.2 Logiciels classiques de gestion de version
1.2.1 subversion et cvs

Figure 2 : Un autre gestionnaire de versions
Ces deux logiciels réalisent une gestion centralisée des différentes versions. Un serveur est dédié à cette tâche. Les utilisateurs ont des droits en lecture/écriture sur les différents fichiers stockés. Un utilisateur peut modifier un fichier, et le renvoyer au serveur qui sera chargé de la fusion de ses modifications avec les fichiers déjà présents.
1.2.2 Git et Mercurial

Figure 3 : Un gestionnaire de version plus proche de Git
Ces deux logiciels ont eux une gestion décentralisée des différentes versions, il n'y a pas un serveur qui stocke les versions, les utilisateurs étant des clients, chaque utilisateur lorsqu'il travaille dispose de la totalité du projet.
Lorsqu'un utilisateur désire travailler, il commence par rapatrier la dernière version 'officielle' du projet. Il réalise son travail en local (sans être nécessairement connecté), puis il soumet son travail. Si personne n'a modifié la version 'officielle', alors ses modifications sont appliquées. Si d'autres modifications ont été apportées, alors un mécanisme automatique de gestion des conflits va être exécuté qui va résoudre automatiquement les situations simples, et qui va proposer une aide pour la gestion des incohérences.
La perte de vitesse de Mercurial ces dernières années peut en grande partie être imputée à l'arrivée et au succès de GitHub et GitLab. Il semble que beaucoup des points les plus attrayants de Mercurial soient maintenant incorporés dans Git.
2 Git
2.1 Présentation

Figure 4 : Git, créé pour le noyau Linux
Git a été créé par L. Torvalds en 2005 afin de permettre une collaboration sur le code du noyau linux. Il est de plus en plus utilisé et de nombreuses entreprises le choisissent pour des projets petits ou gros.
Il existe des serveurs qui regroupent des projets, les plus célèbres étant GitHub (qui est utilisable gratuitement, sous condition que vos projets soient publics) et bitbucket (un peu moins restreint dans sa version gratuite, mais un peu moins utilisé). A l'Isima, on dispose de GitLab qui permet de disposer d'un serveur toujours actif et disponible afin de travailler depuis n'importe quel endroit sur un projet (privé ou public).
2.2 Vocabulaire important : les états
Dans Git un fichier qui fait partie d'un projet peut se trouver dans 3 états différents :
- committed
- le fichier est archivé, il y a eu un point de sauvegarde, et ce fichier n'a pas été modifié depuis ce point.
- modified
- le fichier a été modifié depuis le dernier commit, en général c'est un fichier sur lequel on est actuellement en train de travailler, et dont on n'a pas encore décidé qu'il était temps de l'archiver dans sa version actuelle
- staged
- le fichier a été marqué afin qu'il soit inclut dans le prochain commit
3 Découverte pas à pas
3.1 Sur l'ordinateur de travail
Il n'est pas nécessaire d'avoir un dépôt pour utiliser Git on peut se contenter de travailler sur une unique machine. Le plus gros du travail se passe en général sur la machine locale, et il est possible de décider à n'importe quel moment de :
- créer un dépôt Git sur une machine personnelle, cela nécessite peu de commandes (surtout si on reste dans le classique)
- utiliser un hébergeur comme dépôt, c'est la solution la plus fréquente, elle donne en général de plus accès à des outils de visionnage, de partage, …
3.1.1 Paramétrage de Git en local
Il est nécessaire d'informer Git du nom et de l'adresse courriel, les autres instructions sont classiques mais pas absolument nécessaires.
git config --global --add user.name "Yves-Jean Daniel" git config --global --add user.email "yves-jean.daniel@isima.fr" git config --global core.editor emacsclient -c git config --global pull.rebase true
Pour consulter la configuration actuelle sur la machine de travail, on
utilise git config -l.
- global
- le
--globaldoit être omis si les paramètres configurés sont locaux à un unique projet (en fait assez rare, on a souvent des paramètres qui nous sont propres, mais communs à tous nos projets). - Cohabitation Windows/Linux
- pour ceux qui codent sous windows, les fins
de ligne sont définies par la suite des deux caractères 'CR' (carriage
return) puis 'LF' (line feed), alors que sous Linux elles ne sont
marquées que par 'LF'. Cela pose souvent des problèmes si un travail
fait intervenir les deux types de plateformes. Pour y remédier, on peut
configurer
git config --global core.autocrlf xxx(où xxx peut prendre les valeurs 'true', 'false' ou 'input', consulter la doc simplifiée, oùman git-config). - Editeur
- pour qu'il n'y ait pas de problème avec l'éditeur 'emacsclient'
il est nécessaire qu'un serveur emacs ait été préalablement
lancé. On peut évidemment remplacer cette ligne par un appel à
un autre éditeur. On peut également ajouter dans le
.bashrcla lignealias emacs='emacsclient -c -a "emacs"', et remplacer la ligne définissant l'éditeur dans la config de Git pargit config --global core.editor ec. Il paraît qu'on peut indiquer un autre éditeur, mais qui aurait l'idée de faire une chose pareille ??
3.1.2 Démarrer un projet sur l'ordinateur local
- Créer un répertoire, y entrer,
- Exécuter
git init, cela va créer une arborescence cachée qui va contenir tout ce qui fait la magie de Git. Ne pas hésiter à l'explorer pour mieux comprendre ce qui se passe (attention : on n'a rien à y faire, toute modification doit se faire par des commandes Git et non par des modifications 'à la main' dans cette arborescence).
3.1.3 Créer un premier fichier
Si vous connaissez orgmode, créer un fichier 'readme.org'… sinon un fichier markdown 'readme.md'. Créer au moins un autre fichier.
3.1.4 Ajout d'un fichier
Exécuter git status. On observe que le/les fichiers créés ne font pas
partie du projet. Pour incorporer les fichiers, on utilise git add
NOM_FICHIER ou si on veut inclure tous les fichiers (y compris dans les
sous-répertoires) git add . (ici n'inclure que le fichier 'readme.org' ou
'readme.md').
On observe le nouvel état du projet par git status, et le message indique
que dans le prochain point de sauvegarde (en vocabulaire Git :
commit), il faudra inclure le fichier 'readme'.
- Ajouter en inverse…
Au lieu d'ajouter un par un les fichiers, il est souvent préférable d'utiliser la commande
git add .… mais après avoir précisé les fichiers que l'on ne désire pas ajouter. Cela se fait en créant un fichier ".gitignore" dans le répertoire du projet. C'est un fichier texte, dans lequel on indique sur chaque ligne une sorte d'expression régulière indiquant les fichiers à ignorer. Une bonne introduction est présente ici. - Enlever un fichier
Si on désire ne plus suivre un fichier, on peut le supprimer du suivi par
git reset NOM_FICHIER.
3.1.5 Premiers commits

Figure 5 : The commitments (1991), 14 ans avant les commits de Git
On peut maintenant faire une première photographie (point de sauvegarde, commit) de l'état du projet. Cela se fait au choix par :
git commit- l'éditeur de texte se lance, on écrit une description de ce qui a changé depuis le dernier commit, cela permettra de retourner plus facilement dans le passé si on en a besoin
git commit -m "MESSAGE"- fait la même chose, mais on écrit directement le message, sans passer par l'éditeur, cela suffit si le message est bref.
- Attention
- Même si l'on travaille seul sur un projet, "Le 'moi' de dans trois mois est un autre" (et pour les individus ascendant poisson rouge, demain c'est dans longtemps…). Les messages des commits doivent être utiles !!
Ils sont constitués de :
- une première ligne d'au plus 50 caractères qui explique clairement LA chose qui a été faite (pas 'la' ligne de code : la fonctionnalité ajoutée, le bug corrigé, …)
- une ligne vide
- des explications justifiant ce commit (max 74 caractères par ligne), cette partie est particulièrement importante lorsqu'il y a des décisions à prendre dans des choix lors de fusion de commits incompatibles ; cette partie peut être omise si le message et la situation ne sont pas problématiques.
Un appel à git status indique que le fichier 'readme' est maintenant bien
archivé.
On peut éditer à nouveau le fichier 'readme' en lui ajoutant quelques
modifications. Un git status indique qu'il y a un fichier qui était
précédemment suivi qui a été modifié (le 'readme'), et qu'il y a des
fichiers qui ne font pas partie du suivi.
Pour réaliser un nouveau commit prenant la version mise à jour du fichier on peut au choix :
- refaire un
git add readme.org, suivi d'ungit commit -m "mise à jour du readme"ou, - indiquer que tous les fichiers précédemment suivis doivent faire partie de
ce nouveau commit, et faire le commit :
git commit -a -m "mise à jour du readme".
Si on désire lister les commits qui ont été réalisés, on utilise la commande
git log, qui va lister les derniers commits (on peut préférer git log
--oneline si la ligne de message courte est suffisante, ce qui
est souvent le cas).
On peut ainsi travailler indéfiniment sur sa machine, et même si on ne sait pas encore revenir dans le passé, on sait que tout est archivé et qu'il existe un moyen pour, si on fait une ânerie, récupérer des données perdues… en tous cas tant que le répertoire caché '.git' n'est pas effacé (ou altéré au mauvais endroit).
Avant de faire un commit trop rapide, il peut être intéressant de vérifier :
- tout ce qui a changé :
git diff - tout ce qui a changé dans le fichier 'toto.c' :
git diff toto.c
3.1.6 Les branches
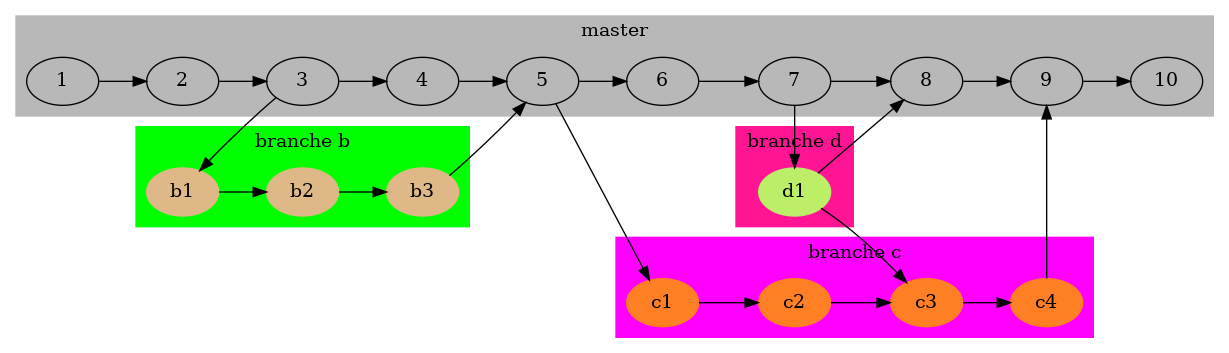
Figure 6 : Les branches de Git
- Avant de commencer
- On peut améliorer la représentation du graphe des branches en insérant dans le
fichier de configuration une ligne qui mettra un peu de couleur dans ce monde un peu terne.
git config --global alias.graph "log --graph --date-order --abbrev-commit --decorate --date=relative --format=format:'%C(bold blue)%h%C(reset) %C(yellow)(%cd)%C(reset) %C(white)%s%C(reset) %C(dim white)- %an%C(reset)%C(bold yellow)%d%C(reset)'"
On peut si on le préfère installer GitGraph qui permet d'obtenir des graphiques plus jolis aisément paramétrables.
Un des points forts de Git est la gestion de 'branches', ce sont des développements en parallèle. Bien entendu, une branche peut elle-même posséder des branches. Usuellement une branche peut correspondre à :
- une fonctionnalité en cours de développement (le plus souvent),
- un développeur
- une version, …
Pour créer une nouvelle branche, on utilise git branch
JOLI_NOM_BRANCHE. Pour se déplacer sur une branche git checkout
JOLI_NOM_BRANCHE (pour revenir sur la branche principale, git checkout
master).
On peut naviguer entre les différentes branches du projet autant qu'on le
désire. Lorsqu'une fonctionnalité est terminée (branche 'super_genial' [En
vrai, choisir des noms pertinents !]), tout le travail qui lui correspond
doit être fusionné avec la branche dont elle est issue (branche 'bof_bof' [no
comment]). Ainsi, la branche 'bof_bof' pourra profiter de ce qui a été fait
dans la branche 'super_genial. Cette opération de fusion se réalise par : se
place sur la branche 'bof_bof' git checkout bof_bof, puis réaliser la
fusion git merge super_genial (résoudre tous les conflits qui en découlent),
puis supprimer le nom de la branche git branch -d super_genial (seul ne nom
est supprimé, les commits qui en faisaient partie sont toujours accessibles ;
il doit exister des cas où on ne supprime pas…).
- Exemple
- branche master
- Créer un fichier bib1.py contenant 3 fonctions fct1, fct2, fct3
- Créer une nouvelle branche 'Dev_fct_4'
- Editer 'bib1.py', lui ajouter une fonction fct5
- Faire le commit qui correspond
- Créer 3 fichiers m1.txt, m2.txt, m3.txt
- Faire le commit qui correspond
- branche dev_fct_4
- Se placer sur la branche 'Dev_fct_4'
- Créer un nouveau fichier 'input_fct4'
- Faire le commit qui correspond
- Editer 'bib1.py', lui ajouter les fonctions fct4
- Faire le commit qui correspond
- Créer une nouvelle branche 'Dev_fct_4a'
- Editer 'bib1.py', créer fct4a
- Faire le commit qui correspond
- Editer la fct fct4a puis commiter deux fois (par exemple vous travaillez 3 fois de suite sur le même problème dans la fonction fct4a)
- branche Dev_fct_4a
- Editer 'bib1.py', créer une fonction fct4a, lui mettre du code
- Faire le commit qui correspond
- branche Dev_fct_4
- Se placer sur la branche 'Dev_fct_4'
- Fusionner avec la branche fct4a : il va y avoir des conflits, il faut éditer les fichiers qui posent problème (ici 'bib1.py'), résoudre les conflits.
- Ré-ajouter le fichier
- Faire le commit avec un message long qui explique comment vous avez arbitré lorsque vous avez dû faire des choix au moment de la fusion
- Editer le fichier 'input_fct4'
- Créer un fichier 'output_fct4'
- Faire le commit qui correspond
- branche master
- Se placer sur la branche 'master'
- Fusionner avec la branche fct4
Pour afficher en mode terminal le graphe des commit, on peut utiliser
git log --oneline --decorate --graph --all - Modifier un commit (dont le message)
Il arrive que l'on désire modifier le message d'un commit, cela se fait par
git commit --amend. Cela s'utilise principalement :- faute de frappe ou de 'bon goût' dans le nom d'un commit ;
- changement du contenu d'un commit (on a fusionné des commits, au contraire on a coupé un commit en plusieurs commits, …).
- Pour s'entrainer
Le site https://learngitbranching.js.org permet de s'exercer dans la pratique des branches.
3.1.7 Se promener dans le passé
Il est possible de naviguer dans les commits passés, et de replacer
l'espace de travail dans cet état (cela ne signifie pas que l'on annule des
actions, c'est une 'visite' dans le passé). Pour réaliser cette opération,
on utilise encore une fois git checkout, mais en précisant le commit où
on désire se rendre : git checkout <commit_id>, ou si on désire
revenir de \(N\) commits en arrière, git checkout HEAD~N. Pour revenir dans
l'état 'présent' git checkout master. HEAD est une étiquette qui
indique la position actuelle dans le projet.
3.1.8 Annuler un commit

Figure 7 : Back to the future!
On désire parfois annuler un commit en particulier dans le passé, cela se
fait par git revert <commit_id>, cela va créer un nouveau commit, qui
correspond à rejouer depuis les commit avant celui qui a été annulé tous les
commits qui le suivent (le commit incriminé n'est pas supprimé, on rejoue le
passé en l'oubliant, et cela crée un nouveau commit, qui comme les autres
pourra être annulé).
3.1.9 Retourner dans un état précédent
Pour revenir dans un état particulier, on commence par se placer à l'endroit
du passé qui nous intéresse par un git checkout <commit_id> (par
exemple), puis on définit ce point comme étant le présent, en perdant tout
ce qui était en cours de travail, par git reset --hard. Cette façon de
procéder peut causer beaucoup de perte de travail et n'est à utiliser
qu'après en avoir bien pesé les conséquences.
3.1.10 TODO Choisir de récupérer uniquement certains éléments de vieux commits
A vous de chercher :)

Figure 8 : C'est le temps de la cueillette.
3.1.11 TODO Découper un commit en plusieurs commits
A vous de chercher :)
3.1.12 Nettoyer, réorganiser ses commits
Il arrive que l'on désire mettre un peu de propre aux commits qui ont étés
réalisés. Grâce à la commande git rebase -i il est possible de :
- fusionner des commits (il est parfois inutile d'avoir 'correction du bug #473' suivi de 'vraie correction du bug #473' suivi de 'annulation de la vraie correction du bug #473' et finalement 'Ca doit être bon pour le bug #473' (life sucks…), et où on préférerait fusionner tout cela, ne serait-ce que pour limiter certains sourires moqueurs à la pause café),
- réordonner les commits ('fonction fct42 (non fini)', 'correction bug #173', 'fonction fct42 (fin) où on a été interrompu pour corriger un bug, on voudrait réordonner, et peut-être après fusionner)
- diviser un commit (le super commit 'beaucoup de trucs', qui est une catastrophe si on a besoin de revenir dans le passé)
3.1.13 Aide pour récupérer

Figure 9 : Git, l'utilitaire dont vous êtes le héros
Seth Robertson a créé un 'jeu' aidant à déterminer la commande la plus adaptée afin de réaliser la récupération adaptée à diverses situations : Une aventure dont vous êtes le héros !
3.2 Sur le site de GitLab
Utiliser un serveur tel que GitLab, GitHub, Gitea,… permet d'avoir accès à un service disponible pour tous sur un temps long, que ce soit pour des projets privés ou des projets publics (on peut monter un serveur chez soi, mais il faudra laisser la machine allumée et s'occuper de sa maintenance). Ces serveurs proposent en général des outils graphiques de reporting ainsi que des mécanismes de gestion de droits fins et faciles d'usage.
3.2.1 Préparer gitlab.isima.fr
Entrer dans 'User Settings / SSH Keys' votre / vos clefs ssh publiques.
3.2.2 Créer un projet sur GitLab
Dans 'Projects / Your Projects / New Project', choisir un nom de projet, laisser le reste par défaut (le projet reste privé).
Dans 'Project Overview / Members', ajouter un camarade comme 'Maintainer' du projet, et un autre comme 'Developper'. Le premier aura tout les droits, le second aura des droits plus restreints.
Dans 'Project overview' on peut voir différentes propositions de code pour les situations suivantes :
- Créer un nouveau dépôt
- on commence un projet sans base préalable,
- Créer un dépôt à partir d'un répertoire
- le contenu du répertoire va constituer la base du projet,
- Récupérer un projet Git
- on récupère un projet, et on le dépose sur GitLab
On choisit de rapatrier le projet d'un des deux membres du groupe (situation 2), l'autre récupère le projet (situation 3). Lors du premier dépôt par le second, il y a vraisemblablement des conflits, les gérer.
3.2.3 Interagir avec le dépôt

Figure 10 : Ce qu'il ne faut pas oublier : MadhavBahl
Pour récupérer ce qui se trouve sur le dépôt, on utilise git pull (qui
grâce à la configuration va réaliser un fetch et un rebase [sans la
config, cela réalise un fetch et un merge, ce qui n'est pas une excellente
idée, mais le rebase n'existait pas à la création en 2005 de Git…]). On peut
préciser une branche par git pull origin branch
En sens contraire, pour déposer ses commits sur le serveur, on utilise git
push, ou pour se limiter à une branche git push origin branch
Pour cloner un dépot distant, on utilise git clone MON_URL MON_REPERTOIRE
permet de cloner un dépôt Git situé à l'url indiquée, dans le répertoire
indiqué. On peut préciser lorsqu'on ne désire pas récupérer tout le passé du
projet l'option --depth=N où \(N\) désigne le nombre de commits passé que
l'on désire récupérer (donc 1 si on ne veut que la dernière version).
4 Et l'ami emacs ?

Figure 11 : Magit
Ce document ne présente pas cet outil, extrêmement puissant et convivial (cela ne se voit peut-être pas au premier coup d’œil… mais il vaut le coup !). Je conseille de ne l'aborder qu'après une certaine pratique de Git en ligne de commande, afin que les concepts soient bien compris.
5 Webographie
- Très basique, parcouru en 5 minutes
- Complet
- Intermédiaire
Certaines pages sur atlassian.com, comme : https://www.atlassian.com/fr/git/tutorials/merging-vs-rebasing
- Vidéos