Rapport sur What the Brainfuck
Table of Contents
- Description de la stratégie
- Partie 1: Définition de certains opérateurs
- Partie 2: Instanciation des variables
- Partie 3: Traitement du programme entré
- Partie 4: Création du stockage de valeur
- Partie 5: Gestion des erreurs de syntaxe
- Partie 6: Gestions des opérateurs simples
- Partie 7: Gestion des opérateurs plus complexes
- Partie 8: Gestion des autres erreurs et affichage du résultat
- Détail algorithmique de la méthode
- Code commenté ayant résolu le problème
- Présentation des tests

Présentation du problème
What the brainfuck est un problème du site Codingame. Il consiste en la programmation d’un langage de programmation se basant sur 8 instructions simples. De plus, ce langage est Turing complet, ce qui signifit que l’on peut l’utiliser afin de coder tout types de programmes. Cela nécessiterait tout de même énormement de patience, car bien que fonctionnel, il est assez embétant à manipuler. Ce codingame a donc pour but de créer l’interpréteur de ce langage, afin que lorsqu’on entre un programme, il nous renvoi son résultat en sortie. Un programme peut être composé des 8 istructions suivantes, elles se basent sur un système de pointeur:
- >: incrémente la position du pointeur
- <: décrémente la position du pointeur
- +: incrémente la valeur de la case sur laquelle se trouve le pointeur
- -: décrémente la valeur de la case sur laquelle se trouve le pointeur
- .: affiche la valeur de la case où se trouve le pointeur sous la forme d’un caractère ASCII
- ,: permet à l’utilisateur de donner une valeur en entrée au programme (forcement un entier positif), et de le stocker dans une case
- [: Se rend directement au crochet fermant ] en ignorant les autres instructions, si la valeur de la case pointée est 0
]: Retourne au crochet ouvrant [ correspondant, n ignorant les autres instructions, si la valeur de la case pointée est différente de 0
Il est important de noter que les crochets fonctionnent par pair, si un crochet est seul cela provoquera une erreur.
Afin que l’interpréteur puisse fonctionner, un appel est composé de trois élements:
- une ligne contenant trois valeurs
- le nombre de lignes du programme
- le nombre de cases dans un tableau contenant les différentes valeurs calculées par l’interpréteur
- le nombre d’entrées écrites par l’utilisateur
- une ou plusieurs lignes qui constituent le programme écrit par l’utilisateur
- les entrées (si il y en a), saisies par l’utilisateur
En effet, dans ce langage on retrouve 3 types d’erreur:
- syntaxe error: l’utilisateur n’a pas respecté l’ouverture et la fermeture des crochets
- pointer out of bound: l’indice du pointeur devient négatif, ou supérieur au nombre de cases spécifiées au début du programme
- incorrect value: la valeur prise par la case est négative ou supérieure à 255
Métode de résolution
Description de la stratégie
Afin de résoudre ce problème Codingame, ma stratégie était assez simple, procéder instruction par instruction afin d’arriver à coder un interpréteur complet et fonctionnel. Pour cela j’ai séparé mon programme en plusieurs parties.
Partie 1: Définition de certains opérateurs
// Fonction qui gère les changements du pointeur int fleche(int p, char f){ if(f=='>'){ p++; return p; }else{ p--; return p; } } // Fonction qui gère le caractère moins int moins(int cell){ cell--; return cell; } // Fonction qui gère le caractère plus int plus(int cell){ cell++; return cell; }
J’ai tout d’abord défini les fonctions qui s’occupaient des instructions les plus simples, comme les + et - qui ne nécessitaient qu’un simple compteur, ou les < et > se basant également sur un compteur.
Partie 2: Instanciation des variables
int L,S,N; int i,j; int k=0; char prog[2000]=""; char prog2[2000]=""; int longueur; scanf("%d%d%d", &L, &S, &N); fgetc(stdin); //Récupération des données de l'énoncé int tab[S]; int entree[100]; int entreecount=N-1; int p=0; int parenthese=0; char rep[200]=""; int c1=0; int c2=1; int c3=0;
Ensuite, il m’a fallut créer un grand nombre de variables, qui allaient me servir tout au long de mon programme. Tout d’abord j’ai dû initialiser les variables qui allaient recevoir les informations du site Codingame. Puis j’ai créé deux tableaux, un permettant de recevoir le programme “brut” écrit par l’utilisateur, et un autre afin de stocker uniquement les instructions de ce programme, sans prendre en compte les commentaires, les espaces et sauts de lignes. Ensuite, j’ai initialisé le tableau et les variables me permettant de gérer le système de pointeur. Enfin, j’ai initialisé différents compteurs qui allaient m’être utiles pour la suite du code.
Partie 3: Traitement du programme entré
// Récupération du programme écrit par l'utilisateur for (i = 0; i < L+N; i++) { char r[1025]; scanf("%[^\n]", r); fgetc(stdin); if((r[0]>='0')&&(r[0]<='9')){ entree[k]=atoi(r); k++; } strcat(prog2,r); } longueur=strlen(prog2); // Stockage de la longueur du programme k=0; // Ecriture de la ligne qui sera interprété par le programme for(i=0;i<longueur;i++){ if((prog2[i]=='+')||(prog2[i]=='-')||(prog2[i]==',')||(prog2[i]=='.')||(prog2[i]=='>')||(prog2[i]=='<')||(prog2[i]=='[')||(prog2[i]==']')){ prog[k]=prog2[i]; k++; } } i=0; k=0;
Dans cette partie, j’ai mis en forme le programme qui allait être interprété. En effet, j’ai tout d’abord récupéré tout les élements écrits par l’utilisateur, le programme brut, que j’ai stocké dans un tableau. Puis dans le second tableau, j’ai uniquement gardé les instructions utiles pour le programme. Cela va me permettre d’obtenir plus facilement le résultat puisqu’il me faudra parcourir un tableau où tous les élements seront utiles.
Partie 4: Création du stockage de valeur
for(i = 0; i < S; i++){ tab[i]=0; } j=0; longueur=strlen(prog); i=0;
Ici, j’ai simplement rempli un tableau de taille S avec des 0. C’est ce tableau qui contiendra les valeurs calculées par le programme.
Partie 5: Gestion des erreurs de syntaxe
for(i=0;i<longueur;i++){ if(prog[i]=='['){ c1++; j=i-1; while((j<longueur)){ // On cherche la seconde parenthèse du couple if(prog[j]=='['){ parenthese+=1; } if((prog[j]==']')&&(parenthese==0)){ j=-7; }else if(prog[j]==']'){ parenthese-=1; } if(j==-7){ // On enregistre que l'on a trouvé c2++; j=longueur+1; } j++; } } parenthese=0; if(prog[i]==']'){ j=i-1; c1++; while((j>-1)){ // On cherche la seconde parenthèse du couple if(prog[j]==']'){ parenthese+=1; } if((prog[j]=='[')&&(parenthese==0)){ j=800; }else if(prog[j]=='['){ parenthese-=1; } if(j==800){ // On enregistre que l'on a trouvé c2++; j=-2; } j--; } } } if((c2<2)&&(c1!=0)){ printf("SYNTAX ERROR"); return 0; } i=0;
Dans cette partie, je regarde si le programme ne contient pas d’erreurs de syntaxe, avant de le compiler. En effet, il ne sert à rien de compiler un programme qui n’a aucune chance de fonctionner. Pour en savoir plus sur le fonctionnement détaillé de cette partie, voir détail algorithmique.
Partie 6: Gestions des opérateurs simples
while(prog[i]!='\0'){ if(prog[i]=='+'){ // Gère l'instruction + tab[p]=plus(tab[p]); } if(prog[i]=='-'){ // Gère l'instruction - tab[p]=moins(tab[p]); } if(prog[i]=='.'){ // Gère l'instruction . char stock; stock=tab[p]; rep[c3]=stock; c3++; } if((prog[i]=='<')||(prog[i]=='>')){ // Gère l'instruction < > p=fleche(p,prog[i]); } if(prog[i]==','){ // Gère l'instruction , tab[p]+=entree[entreecount]; entreecount--; }
Dans cette partie, je commence par créer la boucle principale, qui va permettre d’interpréter le programme écrit, tant que on en est pas arrivé au bout. Alors, pour chaque caractère du programme, le code va vérifier duquel il s’agit et va appliquer les instructions qui lui correspondent. Ici, on retrouve toutes les instructions, sauf les crochets. Certaines font appelle à des fonctions présentées plus haut.
Partie 7: Gestion des opérateurs plus complexes
if(prog[i]=='['){ // Gère l'instruction ] if(tab[p]==0){ j=i; while((j<longueur)){ if(prog[j]=='['){ parenthese+=1; } if((prog[j]==']')&&(parenthese==0)){ i=j; j+=longueur; } else if(prog[j]==']'){ parenthese-=1; } j++; } } } if(prog[i]==']'){ // Gère l'instruction [ if(tab[p]!=0){ j=i-1; while(j>=0){ if(prog[j]==']'){ parenthese+=1; } if((prog[j]=='[')&&(parenthese==0)){ i=j; j=-1; } else if(prog[j]=='['){ parenthese-=1; } j--; } } }
Dans cette septième partie, je traite les instructions crochets. Je vérifie d’abord la valeur de la case désignée par le pointeur, puis j’applique la logique suivante:
- Si le caractère rencontré est un crochet, alors je vérifie que ce soit le crochet correspondant. Si c’est le cas, alors la boucle s’arrête.
- Si le caractère rencontré n’est pas un crochet, ou n’est pas le crochet correspondant, alors la boucle continue.
Partie 8: Gestion des autres erreurs et affichage du résultat
if((p<0)||(p>S-1)){ // Gère les erreurs liées au pointeur printf("POINTER OUT OF BOUNDS"); return 0; } if((tab[p]<0)||(tab[p]>255)){ // Gère les erreurs liées aux valeurs des cases printf("INCORRECT VALUE"); return 0; } i++; } printf("%s",rep); // Affichage du résultat return 0;
Dans cette dernière partie, on s’occupe des derniers élements manquant, rapides à coder. On vérifie d’abord que la valeur de l’indice du pointeur est bien comprise entre les bornes, puis que la valeur de la case est bien comprise entre les bornes et ce pour chaque tour de la boucle while. Enfin, si la boucle while se termine sans avoir renvoyé d’erreur, alors on affiche le résultat du programme, stocké au fur et à mesure dans une variable spéciale.
Détail algorithmique de la méthode
Fonctionnement géneral
Pour avoir une meilleure visibilité sur l’ensemble du programme, voici ci dessous un organigramme montrant le fonctionnement général du code interpréteur.
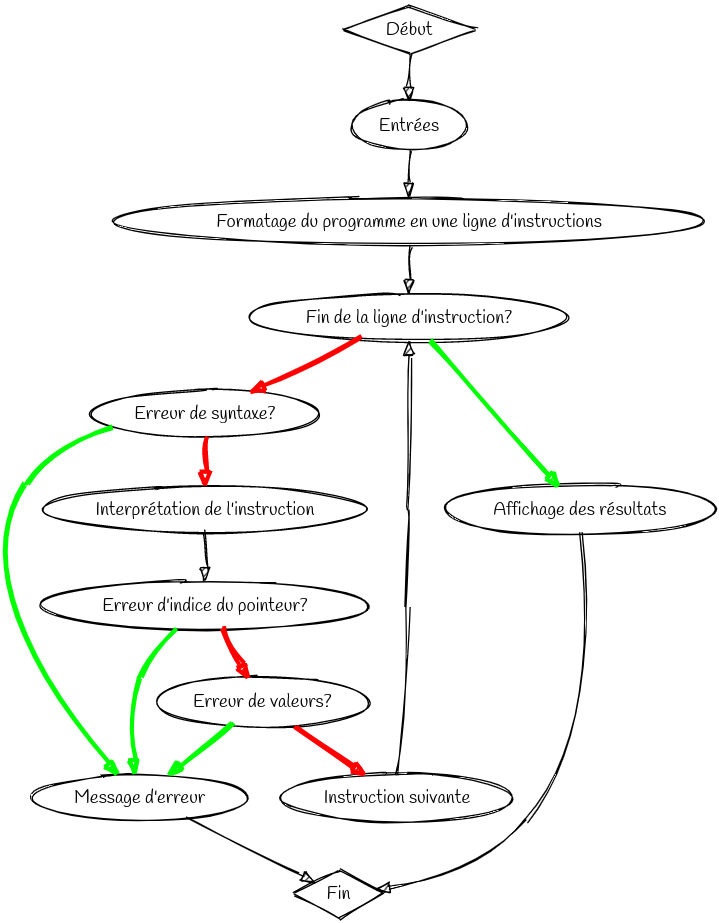
Dans ce schéma, les flèches rouges correspondent à la réponse Non à la question posé. Les flèches vertes correspondent à la réponse oui. Cela nous donnes donc une idée assez générale mais plutot clair du fonctionnement du programme.
Détail de la détection d’erreur de syntaxe
Dans le code, une partie me semblais particulièrement intéressante. C’est pourquoi voici plus en détail, une explication du code sur la détection des erreurs de syntaxe. Le programme va regarder chaque parenthèse, et vérifier si elle est correctement reliée à une autre. Pour comprendre plus en détail comment cela fonctionne, voici un organigramme explicatif.
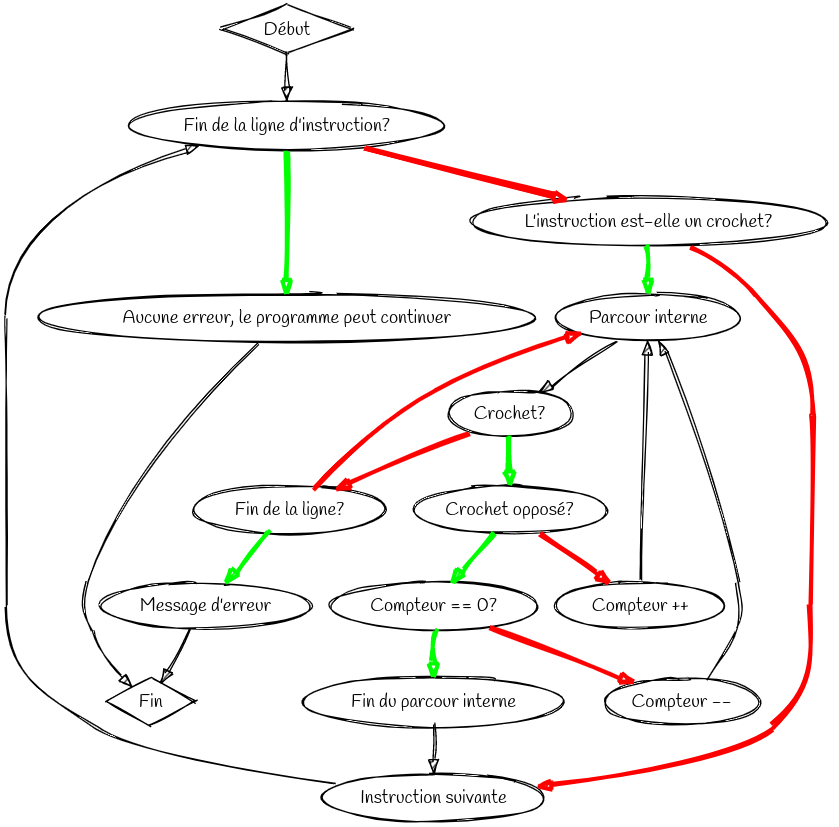
Dans ce schéma, les flèches rouges correspondent à la réponse Non à la question posé. Les flèches vertes correspondent à la réponse oui. On voit que la clé du mécanisme réside dans le compteur. C’est ce dernier qui permet de vérifier si le crocher trouvé est bien relié à celui que l’on vérifie.
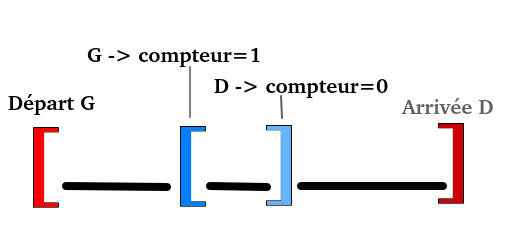
- Exemple
Ici, on souhaite vérifier que le crochet de gauche se ferme correctement. On va alors parcourir les instructions (symbolisées par des traits), jusqu’a trouver un corchet. Ce dernier est également un crochet gauche, donc on ajoute 1 au compteur. Ensuite, on va rencontrer un crochet droit (allant de paire avec le premier crochet bleu). On enlève 1 au compteur, donc si le prochain crochet que l’on trouve est un crochet droit, alors ce sera le crochet que l’on cherche (car le compteur est nul). C’est bien le cas, le crochet suivant est un crochet droit, il correspond bien au premier. Aucune erreur de syntaxe n’est pour le moment détectée. On va alors continuer de la même manière pour les autres crochets du programme, ce qui ne donnera lieu à aucunes erreurs de syntaxe.
Code commenté ayant résolu le problème
Voici ci dessous le code complet m’ayant permis de résoudre le problème.
#include <stdlib.h> #include <stdio.h> #include <string.h> #include <stdbool.h> // Fonction qui gère les changements du pointeur int fleche(int p, char f){ if(f=='>'){ p++; return p; }else{ p--; return p; } } // Fonction qui gère le caractère moins int moins(int cell){ cell--; return cell; } // Fonction qui gère le caractère plus int plus(int cell){ cell++; return cell; } // Fonction principale int main(){ // Instanciation des variables int L,S,N; int i,j; int k=0; char prog[2000]=""; char prog2[2000]=""; int longueur; scanf("%d%d%d", &L, &S, &N); fgetc(stdin); //Récupération des données de l'énoncé int tab[S]; int entree[100]; int entreecount=N-1; int p=0; int parenthese=0; char rep[200]=""; int c1=0; int c2=1; int c3=0; // Récupération du programme écrit par l'utilisateur for (i = 0; i < L+N; i++) { char r[1025]; scanf("%[^\n]", r); fgetc(stdin); if((r[0]>='0')&&(r[0]<='9')){ entree[k]=atoi(r); k++; } strcat(prog2,r); } longueur=strlen(prog2); // Stockage de la longueur du programme k=0; // Ecriture de la ligne qui sera interprété par le programme for(i=0;i<longueur;i++){ if((prog2[i]=='+')||(prog2[i]=='-')||(prog2[i]==',')||(prog2[i]=='.')||(prog2[i]=='>')||(prog2[i]=='<')||(prog2[i]=='[')||(prog2[i]==']')){ prog[k]=prog2[i]; k++; } } i=0; k=0; // Création du tableau qui stockera le résultat du programme entré for(i = 0; i < S; i++){ tab[i]=0; } j=0; longueur=strlen(prog); i=0; // Vérification de la syntaxe for(i=0;i<longueur;i++){ if(prog[i]=='['){ c1++; j=i-1; while((j<longueur)){ // On cherche la seconde parenthèse du couple if(prog[j]=='['){ parenthese+=1; } if((prog[j]==']')&&(parenthese==0)){ j=-7; }else if(prog[j]==']'){ parenthese-=1; } if(j==-7){ // On enregistre que l'on a trouvé c2++; j=longueur+1; } j++; } } parenthese=0; if(prog[i]==']'){ j=i-1; c1++; while((j>-1)){ // On cherche la seconde parenthèse du couple if(prog[j]==']'){ parenthese+=1; } if((prog[j]=='[')&&(parenthese==0)){ j=800; }else if(prog[j]=='['){ parenthese-=1; } if(j==800){ // On enregistre que l'on a trouvé c2++; j=-2; } j--; } } } if((c2<2)&&(c1!=0)){ printf("SYNTAX ERROR"); return 0; } i=0; // Boucle qui interpréte le programme while(prog[i]!='\0'){ if(prog[i]=='+'){ // Gère l'instruction + tab[p]=plus(tab[p]); } if(prog[i]=='-'){ // Gère l'instruction - tab[p]=moins(tab[p]); } if(prog[i]=='.'){ // Gère l'instruction . char stock; stock=tab[p]; rep[c3]=stock; c3++; } if((prog[i]=='<')||(prog[i]=='>')){ // Gère l'instruction < > p=fleche(p,prog[i]); } if(prog[i]==','){ // Gère l'instruction , tab[p]+=entree[entreecount]; entreecount--; } if(prog[i]=='['){ // Gère l'instruction ] if(tab[p]==0){ j=i; while((j<longueur)){ if(prog[j]=='['){ parenthese+=1; } if((prog[j]==']')&&(parenthese==0)){ i=j; j+=longueur; } else if(prog[j]==']'){ parenthese-=1; } j++; } } } if(prog[i]==']'){ // Gère l'instruction [ if(tab[p]!=0){ j=i-1; while(j>=0){ if(prog[j]==']'){ parenthese+=1; } if((prog[j]=='[')&&(parenthese==0)){ i=j; j=-1; } else if(prog[j]=='['){ parenthese-=1; } j--; } } } if((p<0)||(p>S-1)){ // Gère les erreurs liées au pointeur printf("POINTER OUT OF BOUNDS"); return 0; } if((tab[p]<0)||(tab[p]>255)){ // Gère les erreurs liées aux valeurs des cases printf("INCORRECT VALUE"); return 0; } i++; } printf("%s",rep); // Affichage du résultat return 0; }
Présentation des tests
Afin de coder ce programme et de le valider, il a fallut passer plusieurs tests. Alors voici ci dessous les tests qui m’ont permi de résoudre ce problème.
Test 1
- Entrée
1 1 0 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++.+.+.
- Sortie
ABC
Ce premier test permet de coder le coeur de l’interpréteur. En effet il nous aide à instancier les différentes variables et à coder les premières instructions simples (+,-,.). Il permet également de coder l’affichage du résultat et la boucle qui parcourt le programme.
Test 2
- Entrée
1 4 0 ++++++++++[>+++++++>++++++++++>+++<<<-]>++.>+.+++++++..+++.>++.<<+++++++++++++++.>.+++.------.--------.>+.
- Résultat
============Test passé============ ==============Sortie============== Hello World! ==================================
Ce second test permet de continuer à coder les instructions. Dans celui ci apparaissent les instructions [,],<,>. Il faut donc réussir à coder le système permettant de retrouver les couples de crochets. Le système pour les flèches nécessite moins de temps. Alors, une fois ce test passé, il est déja possible d’interpréter un certain nombre de programme. Mais l’interpréteur est loin d’être entièrement fonctionnel.
Résultats des test 1 à 9
========Test numero 1 passe======== ==============Sortie============== ABC ================================== ========Test numero 2 passe======== ==============Sortie============== Hello World! ================================== ========Test numero 3 passe======== ==============Sortie============== $ ================================== ========Test numero 4 passe======== ==============Sortie============== Hello World! ================================== ========Test numero 5 passe======== ==============Sortie============== POINTER OUT OF BOUNDS ================================== ========Test numero 6 passe======== ==============Sortie============== INCORRECT VALUE ================================== ========Test numero 7 passe======== ==============Sortie============== SYNTAX ERROR ================================== ========Test numero 8 passe======== ==============Sortie============== SYNTAX ERROR ================================== ========Test numero 9 passe======== ==============Sortie============== POINTER OUT OF BOUNDS ==================================
Remarques sur les tests précedents
- Test 3
Dans ce test apparait le système d’entrée par l’utilisateur. Il permet donc de tester son bon fonctionnement.
- Test 4
Jusqu’à présent mon interpréteur prenait directement le programme “brut”. Mais suite à ce test, il m’a fallut coder des instructions afin de ne récupérer dans le programme saisi, que les morceaux utiles pour l’interpréteur. Au final, on se rend compte que le programme donne le même résultat que le test 2.
- Test 5
Avec le test 5, il m’a fallut implémenter la vérification des erreurs d’indices pointeur. Cela n’a pas nécessité de variables supplémentaires, mais uniquement une instruction if.
- Test 6
Le test 6 est similaire au test 5 au niveau des lignes de code à implémenter. Il traite des erreurs de valeurs. Il me fallait donc rajouter une autre instruction if à la fin du programme.
- Test 7
Ce test traite des erreurs de syntaxe. Il a été plus compliqué à passer que les autres. En effet, à l’origine, j’avais implémenté deux compteurs qui vérifiaient le nombre de crochets ouvrant et fermant. Mais cela ne fonctionnait pas toujours. Par exemple regardons le test 7.1 ci dessous.
- Test 8
Si on utilise la méthode du double compteur pour ce test, le programme n’affiche pas d’erreur de syntaxe, pourtant il y en a une. En effet, même si le nombre de crochet ouvrant et fermant est le même, le crochet fermant se trouve avant le crochet ouvrant, ce qui est impossible. Donc il m’a fallu reprendre la méthode utilisée pour le code de l’instruction crochet, et le modifier afin de l’adapter à cette situation.
- Test 9
Ce test est le dernier test. Il nous permet de vérifier l’ordre de priorité des erreurs. En effet, avant de faire ce test, j’avais implémenté la vérification syntaxique à la fin de l’interpréteur, ce qui n’était pas très malin. Il m’a donc permi de me rendre compte que ce n’était pas la bonne chose à faire, et en l’implémentant au début de l’interpréteur, le Codingame était résolu.
Description d’une autre solution au problème
J’ai choisi de présenter la solution de l’utilisateur MJZ car elle est extrèmement compacte et utilise très peu de variables comparé à la mienne. Voici ci dessous le fonctionnement par étape de cette solution.
Partie 1: Vérification des erreurs de syntaxe
void checkBrackets(char* p){ int depth = 0; for(; *p; p++){ if(*p == '[') depth++; if(*p == ']') depth--; if(depth < 0) exit(puts("SYNTAX ERROR")); } if(depth) exit(puts("SYNTAX ERROR")); }
MJZ commence d’abord par définir une fonction chargée de la gestion des erreurs de syntaxe. Pour cela, il utilise une méthode similaire à celle détaillée plus haut. Il initialise un compteur qu’il fait diminuer ou augmenter selon les crochets trouvés, et vérifie si toutes les pairs de crochet sont bien placées.
Partie 2: Instruction crochet
void search(int dir){ int depth = dir; while(depth){ pProgram += dir; if(prog[pProgram] == '[') depth++; if(prog[pProgram] == ']') depth--; } }
L’utilisateur va ensuite définir une fonction similaire, cette fois ci chargé de gérer l’instruction crochet.
Partie 3: Récupération du programme
int lines, storageSize, inputs; scanf("%d%d%d\n", &lines, &storageSize, &inputs); for(int i = 0; i < lines; i++) { char line[1025]; fgets(line, 1025, stdin); strcat(prog, line); } checkBrackets(prog);
Ensuite, dans le programme principal, l’utilisateur va commencer par récupérer le code fourni, ainsi que les diverses informations disponibles, comme le nombre de ligne du programme, ou encore la taille du tableau de stockage. Puis, il va appeler la fonction qui vérifie la syntaxe et va l’appliquer au programme.
Partie 4: Interprétation du programme
for(;; pProgram++) switch(prog[pProgram]){ case '>': if(++pStorage >= storageSize) return puts("POINTER OUT OF BOUNDS"); break; case '<': if(--pStorage < 0) return puts("POINTER OUT OF BOUNDS"); break; case '+': if(++storage[pStorage] > 255) return puts("INCORRECT VALUE"); break; case '-': if(--storage[pStorage] < 0) return puts("INCORRECT VALUE"); break; case '.': output[pOutput++] = storage[pStorage]; break; case ',': scanf("%d", &storage[pStorage]); break; case '[': if(storage[pStorage] == 0) search(+1); break; case ']': if(storage[pStorage] != 0) search(-1); break; case 0: return puts(output); }
Enfin, à l’aide d’une boucle for et d’un switch, l’utilisateur va parcourir le programme et effectuer les actions propres à chaque instruction. Pour les instructions crochets il fera appel à la fonction définie plus haut. A chaque action, l’interpréteur va vérifier si il n’y a pas d’erreur.
Voici ci dessous le code commenté complet de l’utilisateur MJZ.
#include <stdlib.h> #include <stdio.h> #include <string.h> char output[10000], prog[100*1025]; int storage[100], pStorage, pProgram, pOutput; // Vérification des erreurs de syntaxe void checkBrackets(char* p){ int depth = 0; for(; *p; p++){ if(*p == '[') depth++; if(*p == ']') depth--; if(depth < 0) exit(puts("SYNTAX ERROR")); } if(depth) exit(puts("SYNTAX ERROR")); } // Instruction crochet void search(int dir){ int depth = dir; while(depth){ pProgram += dir; if(prog[pProgram] == '[') depth++; if(prog[pProgram] == ']') depth--; } } // Début du programme principal int main{ int lines, storageSize, inputs; scanf("%d%d%d\n", &lines, &storageSize, &inputs); for(int i = 0; i < lines; i++) { char line[1025]; fgets(line, 1025, stdin); strcat(prog, line); } checkBrackets(prog); // Interprétation du programme et affichage du résultat for(;; pProgram++) switch(prog[pProgram]){ case '>': if(++pStorage >= storageSize) return puts("POINTER OUT OF BOUNDS"); break; case '<': if(--pStorage < 0) return puts("POINTER OUT OF BOUNDS"); break; case '+': if(++storage[pStorage] > 255) return puts("INCORRECT VALUE"); break; case '-': if(--storage[pStorage] < 0) return puts("INCORRECT VALUE"); break; case '.': output[pOutput++] = storage[pStorage]; break; case ',': scanf("%d", &storage[pStorage]); break; case '[': if(storage[pStorage] == 0) search(+1); break; case ']': if(storage[pStorage] != 0) search(-1); break; case 0: return puts(output); } }
Programmes réalisé à l’aide de Brainfuck
Affiche mon prénom
Majuscule
Bilan de ce travail
Pour conclure, ce travail m’a appris à construire mon programme au fur et à mesure des tests, sans vouloir tout écrire d’une traite. De plus, il m’a permis de renforcer mes connaissances en Babel. Enfin, cela m’a fait découvrir un nouveau langage de programmation, et bien que très peu pratique, cela a enrichi ma culture personnelle informatique.