


Date de première publication : 2019/11/07
Préparation
Objectif et contexte
L'objectif de cet exercice est de continuer la découverte de SpringBoot avec l'utilisation de Java Persistance API (JPA).
Vous allez réaliser une application qui permet à un utilisateur de noter des tâches à faire et de les ordonner en "à faire", "en cours" et "terminé".
L'environnement de développement est le suivant :
- Java : Java SE 17 ou 21
- Gradle 8.5+ ou Gradlew
- SpringBoot 4
Ce sujet utilise les documentations officielles de Spring Boot suivantes :
- "accessing datajpa"
- "relational data access"
- "accessing data mysql"
- "accessing data rest"
- "rest hateoas"
On ne cherche pas à manipuler une base non relationnelle et on ne cherche pas à faire une architecture REST (pas encore).
Quelques concepts
Grâce à Spring Data, Spring permet de manipuler tous les types de bases de données mais nous allons nous limiter aux bases relationnelles. On peut les manipuler à différents niveaux : rester au plus proche du SGBD choisi (JDBC avec connecteur) à une abstraction complète avec ORM (Object Relational Machine) nommée JPA.
| Java |
| ORM |
| JDBC |
| Base de données |
De nombreux moteurs sont utilisables pour Spring : Oracle, MySQL/MariaDB, posgreSQL, derby (aka JavaDB) et h2... Malheureusement, l'implémentation de JPA utilisée, Hibernate, ne supporte pas facilement actuellement SQLite (il y a pas de mal configuration à faire et il faut fournir un Dialect entre autres). On utilisera la base H2 (écrite en Java) en mode embedded (pas serveur) et fichier (pas inmemory). On aurait pu utiliser derby qui est fourni avec le JDK.
Modélisation et SQL
Nous allons gérer des tâches / post-its / notes. Ces tâches seront rangées par catégorie. Une tâche possède donc un contenu, une catégorie, une date de création et une date pour laquelle le travail doit être fait. Une catégorie est un simple nom.
Voici le code SQL pour générer les tables tasks et categories, le SQL est
DROP TABLE tasks IF EXISTS;
DROP TABLE categories IF EXISTS;
CREATE TABLE categories (
category_id IDENTITY PRIMARY KEY,
name VARCHAR(20) DEFAULT ''
);
INSERT INTO categories(name) values('todo');
INSERT INTO categories(name) values('wip');
INSERT INTO categories(name) values('done');
CREATE TABLE tasks (
task_id IDENTITY PRIMARY KEY,
category INTEGER NOT NULL,
content VARCHAR(500) NOT NULL,
creation_date DATE DEFAULT CURRENT_DATE(),
end_date DATE DEFAULT NULL,
FOREIGN KEY(category) REFERENCES categories(category_id)
);
INSERT INTO tasks (category, content) values(3, 'finir le tp 1');
INSERT INTO tasks (category, content) values(2, 'finir le tp 2');
INSERT INTO tasks (category, content) values(1, 'finir le tp 3');
Mise en place du projet
Il faut créer un nouveau projet Spring Boot et choisir les options suivantes :
On a sélectionné les options suivantes :
- Project : Gradle - groovy - le logiciel d'automatisation
- Langage : Java
- Spring Boot : 4.0.1 - la version stable la plus récente
- Dependencies
- Spring Boot DevTools
- Spring Web (pour faire une application Web)
- Thymeleaf
- Lombok
- H2
- JDBC API
- SpringData JPA
- SpringData JDBC
- Project Metadata
- Group : app
- Artifact : tasks
- Name : Tasks
- Package name : app
- Java : 17
En résumé, c'est le même fichier de configuration classiques avec des dépendances supplémentaires :
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
implementation 'org.springframework.boot:spring-boot-starter-thymeleaf'
implementation 'org.springframework.boot:spring-boot-starter-web'
compileOnly 'org.projectlombok:lombok'
developmentOnly 'org.springframework.boot:spring-boot-devtools'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}Manipuler une base avec JDBC
Création de la base
Nous allons coder une application principale qui sera capable de créer une base de départ (structure et données). Pour cela, on va analyser la ligne de commande (il faut implémenter l'interface CommandLineRunner :
package app;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.CommandLineRunner;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
@SpringBootApplication
public class TasksApplication implements CommandLineRunner {
private static final Logger log = LoggerFactory.getLogger(TasksApplication.class);
@Autowired
JdbcTemplate jdbcTemplate;
public static void main(String[] args) {
SpringApplication.run(TasksApplication.class, args);
}
@Override
public void run(String... strings) throws Exception {
List<String> list = Arrays.asList(strings);
if (list.contains("install")) {
// le code de création de la base
// voir ci-dessous
}
}
}
Deux attributs ont été déclarés : le premier log va permettre d'afficher des informations sur l'exécution du programme (vous pourriez aussi utiliser les sorties standards), le second jdbcTemplate est créé automatiquement par Spring et va permettre de manipuler la base de données directement avec JDBC.
Si le paramètre install est détecté à l'exécution, la base sera créée sinon l'étape sera sautée.
gradle bootRun --args='install'
Il ne faut pas oublier de spécifier dans quelle base de données nous travaillons (type, inmemory, serveur, ...). Cela se configure dans le fichier application.properties. Par exemple, cela donne :
spring.jpa.hibernate.ddl-auto=none
spring.datasource.url=jdbc:h2:file:./toudou
Le paramètre ddl-auto est spécifique à Hibernate : il permet de spécifier si la structure de la base de données doit être créée par l'ORM si elle n'existe pas. Si la base est créée par JDBC, laissez le paramètre à none sinon passez le à update
Le code de génération (ddl ou data definition language :-)) qui s'appuie sur le modèle de données se trouve ci-dessous :
jdbcTemplate.execute("DROP TABLE tasks IF EXISTS");
jdbcTemplate.execute("DROP TABLE categories IF EXISTS");
jdbcTemplate.execute(
"CREATE TABLE categories ("+
"category_id IDENTITY PRIMARY KEY," +
"name VARCHAR(20) DEFAULT '' "+
");" );
log.info("categories TABLE CREATED");
jdbcTemplate.update("INSERT INTO categories(name) values('todo'); ");
jdbcTemplate.update("INSERT INTO categories(name) values('wip'); ");
jdbcTemplate.update("INSERT INTO categories(name) values('done'); ");
log.info("categories TABLE POPULATED");
jdbcTemplate.execute(
"CREATE TABLE tasks (" +
" task_id IDENTITY PRIMARY KEY," +
" category INTEGER NOT NULL," +
" content VARCHAR(500) NOT NULL," +
" creation_date DATE DEFAULT CURRENT_DATE(), " +
" end_date DATE DEFAULT NULL, " +
" FOREIGN KEY(category) REFERENCES categories(category_id)"+
");");
log.info("tasks TABLE CREATED");
// un peu de data manipulation language ou DML
jdbcTemplate.update("INSERT INTO tasks (category, content) values(3, 'finir le tp 1'); ");
jdbcTemplate.update("INSERT INTO tasks (category, content) values(2, 'finir le tp 2'); ");
jdbcTemplate.update("INSERT INTO tasks (category, content) values(1, 'finir le tp 3'); ");
jdbcTemplate.update("INSERT INTO tasks (category, content) values(1, 'finir le tp 3'); ");
log.info("tasks TABLE POPULATED");
Les mots-clés peuvent changer en fonction des SGBDs ou en fonction des versions : pour CURRENT_DATE(), on peut trouver aussi NOW(), TODAY(), ...
Utilisation de la base avec JDBC
On peut vérifer que les tables sont correctement créées avec le même genre de code : le programme peut réagir à une commande test par exemple. Le premier code permet de lire la table categories avec une lambda et stocke les informations dans une liste :
List<String> categories;
String sql = "select * from categories";
categories = jdbcTemplate.query(sql,
(rs, rowNum) ->
{ return new String (rs.getString("name") );
}
);
log.info(categories.toString());
Le deuxième code permet de lire la table tasks
sql = "SELECT * FROM tasks";
List<Map<String, Object>> rows = jdbcTemplate.queryForList(sql);
for (Map row : rows) {
log.info(row.get("content").toString());
log.info(categories.get((Integer)row.get("category")-1));
}
Console h2
Tant que votre serveur est en train de tourner, une console h2 est disponible à l'url http://localhost:8080/h2-console/
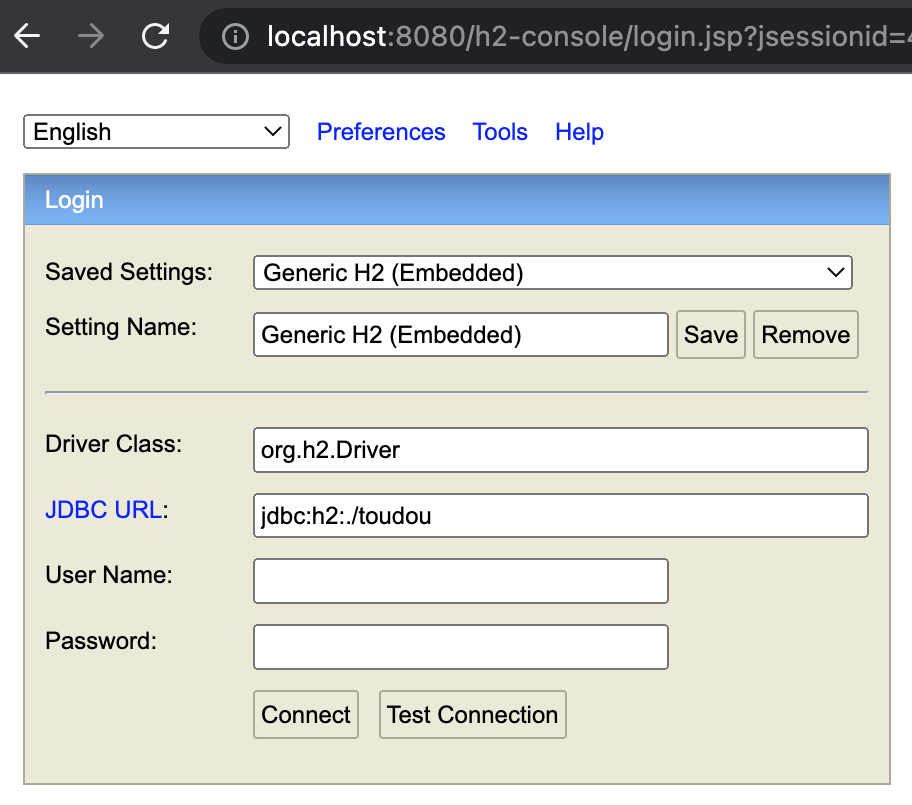
Connectez-vous sans login ni mot de passe en utilisant la chaine de connexion du fichier application.properties
Affichage web
À l'instar du TP précédent, vous pouvez créer une vue pour afficher les tâches à faire. Il suffit d'ajouter la liste des choses à faire au modèle quand on écrit le contrôleur. Si on passe la liste avec un modèle, cela va donner :
<h1>Choses à faire</h1>
<p th:if="${rows.isEmpty()}">Aucune tâche à afficher</p>
<table th:unless="${rows.isEmpty()}">
<tr th:each="row: ${rows}">
<td th:text="${row.get('note_id')}"></td>
<td th:text="${row.get('content')}"></td>
</tr>
</table>
On utilise la méthode get() car row est une Map
On va pas aller plus loin sur l'utilisation directe de JDBC.
Manipulation avec JPA (Hibernate)
Ce que l'on a fait est un peu trop "SGBD" à mon goût. Il est possible de gérer des objets, appelés entités, plutôt que des tuples de table. Pour ce faire, il faut créer des classes et expliciter, si nécessaire, la correspondance (mapping) entre l'attribut de l'objet et la colonne de la table. La configuration par convention est appliquée sauf si elle est modifiée par annotation.
À chaque table correspond une classe (et à chaque tuple, un objet)
Voici le code de la classe Category :
package app.entities;
import jakarta.persistence.Entity;
import jakarta.persistence.Table;
import jakarta.persistence.Column;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
@Entity
@Table(name="categories")
public class Category {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="category_id")
private Long id;
private String name;
protected Category() {}
public Category(String name) {
this.name = name;
}
@Override
public String toString() {
return String.format(
"Category[id=%d, name='%s']", id, name);
}
// il va falloir mettre les getters/setters
// c'est hyper important pour le binding
// voir la note plus bas
}
Et celui de la classe Task :
package app.entities;
import jakarta.persistence.Entity;
import jakarta.persistence.Table;
import jakarta.persistence.Column;
import jakarta.persistence.GeneratedValue;
import jakarta.persistence.GenerationType;
import jakarta.persistence.Id;
import jakarta.persistence.OneToOne;
import jakarta.persistence.ManyToOne;
import jakarta.persistence.JoinColumn;
import org.hibernate.annotations.CreationTimestamp;
import java.util.Date;
@Entity
@Table(name="tasks")
public class Task {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
@Column(name="task_id")
private Long id;
@ManyToOne
@JoinColumn(name = "category")
private Category category;
private String content;
@Column(name="creation_date")
@CreationTimestamp
private Date creationDate;
@Column(name="end_date")
private Date endDate;
protected Task() {}
public Task(Category category, String content ) {
this.category = category;
this.content = content;
//this.creationDate = new Date();
}
@Override
public String toString() {
return String.format(
"Task[id=%d, content='%s', category='%s']", id, content, category);
}
// il faut mettre les getters et les setters
// voir la note plus bas
}
Les clés primaires avec la génération automatique sont spécifiées @Id et @GeneratedValue, les clés étrangères également (@JoinColumn et @ManyToOne.
Si les noms de table ou de colonne sont différents de la configuration par convention, un paramètre name vient corriger cela (@Table et @Column.
Les getters et les setters n'ont pas été écrits. Vous pouvez :
- les écrire à la main
- les générer avec votre EDI
- utiliser le projet lombok pour bénéficier des annotations
@Getteret@Settersur les attributs.
Si vous oubliez un setter par exemple, le binding ne vous permettra pas de mettre à jour l'objet mais vous n'aurez aucune erreur.
Ces classes vont permettre de créer des entités gérées par un repository à écrire pour chaque entité. Le repository est le DAO de SpringBoot. Vous pouvez utiliser CrudRepository ou son interface fille JpaRepository
package app.repositories;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
import app.entities.Category;
public interface CategoryRepository
extends CrudRepository<Category, Long> {
}Grâce à Spring, il n'est pas nécessaire d'écrire plus. Les méthodes vont être implémentées automatiquement. Vous devez tout de même écrire l'interface TaskRepository
Dans l'application, pour pouvoir utiliser un tel repository, il faudra encore laisser la magie de Spring faire :
// import org.springframework.beans.factory.annotation.Autowired;
@Autowired
TaskRepository taskRepository;
Ce repository permet de faire toutes les requêtes nécessaires et les créations voulues. Vous pouvez par exemple ajouter de nouveaux tuples en base avec le code suivant :
Task task = new Task(categoryRepository.findById(1L).get() ,
"essai en cours");
taskRepository.save(task);
On va exploiter les requêtes dans la section suivante.
Interface utilisateur
Voici les pages et les actions que l'on aimerait réaliser :
| / | GET | Lister toutes les tâches : |
| /tasks | GET | Lister toutes les tâches |
| /tasks/new | GET | Afficher une page pour créer une tâche |
| /tasks | POST | Créer une nouvelle tâche |
Et si on voulait être exhaustif :
| /tasks/:id | GET | Afficher la tâche donnée |
| /tasks/:id/edit | GET | Afficher un formulaire pour modifier la tâche |
| /tasks/:id | PATCH/PUT | Modifier la tâche donnée |
| /tasks/:id | DELETE | Effacer la tâche donnée |
Affichage des tâches
Nous allons écrire une page web - un template - pour afficher les tâches. La navigation implique d'écrire un contrôleur :
package app.controllers;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.ui.Model;
import app.entities.Task;
import app.repositories.TaskRepository;
@Controller
public class IndexController {
@Autowired
private TaskRepository taskRepository;
@GetMapping(path={"/", "/tasks"})
public String getAllTasks(Model model) {
model.addAttribute("tasks", taskRepository.findAll());
return "tasks";
}
}
Voici maintenant le template nécessaire pour afficher toutes ces tâches :
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Liste des tâches</title>
</head>
<body>
<h1>Tâches à faire</h1>
<p th:if="${tasks.isEmpty()}">Aucune tâche à afficher</p>
<div th:each="t : ${tasks}" th:unless="${tasks.isEmpty()}" >
<div th:text="${t.category.name}"></div>
<div th:text="${t.content}"></div>
<div th:text="${t.creationDate}"></div>
<div th:text="${t.endDate}"></div>
</div>
</body>
</html>
La liste des tâches est passée en paramètre au modèle de la page et l'attribut th:each permet d'itérer chacun des objets.
tasks est un Iterable de Task. Écrire t.content en Thymeleaf n'est pas un accès à l'attribut mais il y a bien un appel aux méthodes getContent() et setContent() de l'objet.
Ajouter une tâche
Je vous propose d'ajouter une méthode au contrôleur pour ajouter une nouvelle tâche. Les données seront tirées d'un formulaire (une page à concevoir). Si vous respectez les règles usuelles de nommage, la création se fera avec la même URL que la consultation des tâches mais avec le verbe POST
@PostMapping(path="/tasks")
public String nouveau() {
return "redirect:/tasks";
}Pour afficher une tâche particulière, il faut modifier l'URL d'accès :
http://localhost:8080/tasks/3
Cela peut se faire simplement avec une méthode du contrôleur :
@XXXMapping(value = "/tasks/{id}")
public String YYY(@PathVariable("id") int id, Model model) {
return ...
}XXX est bien entendu relatif au verbe HTTP : GET pour voir, PUT ou PATCH pour modifier et DELETE pour effacer ...
YYY est un nom de méthode qui importe peu mais que vous aurez choisi avec soin :-)
C'est un peu fastidieux mais faisable bien entendu !!!
Une pincée poignée de présentation
En plus de l'exemple, en début de TP, j'aime bien les présentations suivantes :
- https://code.tutsplus.com/tutorials/create-a-sticky-note-effect-in-5-easy-steps-with-css3-and-html5--net-13934
- https://www.bootdey.com/snippets/view/notes-dashboard
En fonction de ce que vous savez ou vous voulez apprendre : on peut faire cela avec un framework CSS ou pas, un framework JS ou pas.
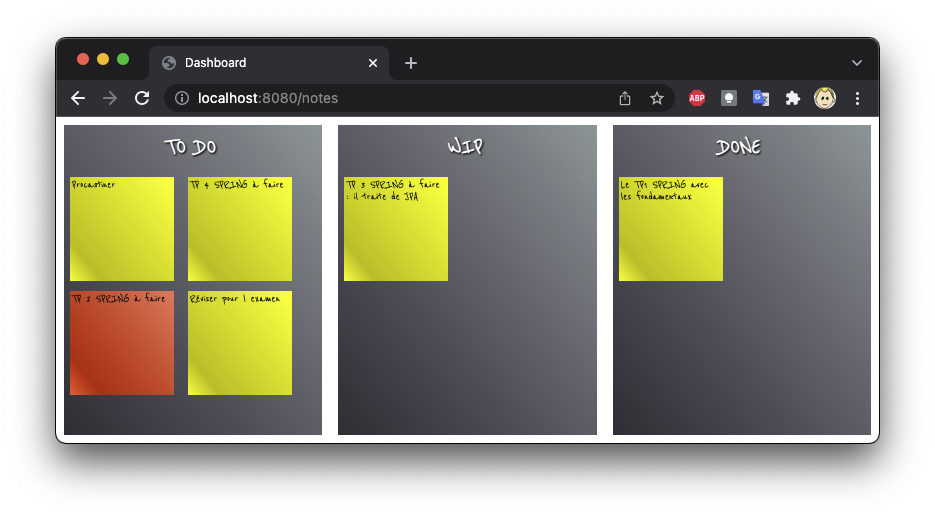
La suite de l'exercice va se faire suivant l'exemple donné plus haut : les tâches sont réparties sur trois tableaux
Si vous ne savez pas où vous en êtes, voici une piste de démarrage..
Nous avons besoin de lister les tâches par categorie.
Cette méthode n'est pas disponible dans taskRepository,
il faut l'ajouter puis il faut modifier la page d'affichage pour afficher les listes.
Pour mettre du style dans la page, trois deux possibilités :
un attribut dédiéstyle- une balise
styledans l'entête - une balise
linkpour donner le style dans un fichier d'extension .css
Voilà ce qu'il faut faire :
- Afficher les trois colonnes les unes à côté des autres
- Faire que les titres des colonnes ne bougent pas
- Afficher les tâches sous forme de post-its : des rectangles de même taille ...
On part du principe qu'il n'y a que 3 colonnes alors que les categories sont lues dans une base. On pourrait s'amuser à générer le css grâce à thymeleaf.
Afficher les colonnes
On peut utiliser le mode grille ou flex ... ou inline-block ou flottant ...
#main {
display: grid;
grid-template-columns: repeat(3, 1fr);
grid-column-gap: 10px;
grid-auto-rows: minmax(100px, auto);
height: 100vh;
}
.zone {
font-size:0; /* bogue des espaces */
position: relative;
overflow-y: auto;
padding : 4px 4px 4px 4px;
background: rgb(52,52,59);
background: linear-gradient(51deg, rgba(52,52,59,1) 0%, rgba(87,87,97,1) 35%, rgba(150,159,161,1) 100%);
}
Afficher les tâches
.task {
display:inline-block;
width:100px;
height:100px;
margin:2px;
padding:2px;
font-size:12px; /* 12 pixels pour 300px */
background: rgb(252,252,40);
background: linear-gradient(51deg, rgba(252,252,40,1) 0%, rgba(194,194,3,1) 17%, rgba(255,255,42,1) 100%);
overflow:hidden;
}Et le déplacement dans tout ça ?
Pour faire cela, il va falloir écrire du javascript côté client
- changement de la catégorie avec un requête ajax ou à défaut, rechargement de la page après opération
- drag and drop des posts-its/tâches à la souris
Je vous propose d'écrire le code pour changer la catégorie d'une tâche. Par exemple, avec l'URL : /tasks/1/done. Le verbe à utiliser est PATCH (on ne change qu'une partie de la ressource. Si ce verbe n'est pas supporté par le conteneur de servlets, vous utiliserez PUT)
Le code javascript suivant permet de changer la catégorie de la tâche 1 au clic de la souris (à mettre dans une balise <script>à la toute fin de la balise body). C'est de l'AJAX avec la méthode FETCH :
var myHeaders = new Headers();
var myInit = { method: 'PATCH',
headers: myHeaders,
mode: 'cors',
cache: 'default' };
window.addEventListener("click", function(event) {
console.log("click");
fetch('/tasks/1/done',myInit)
.then(function(response) {
console.log("PUT done");
window.location.reload();
});
});
On pourrait utiliser les attributs de données personnalisées sur une balise pour connaître l'identifiant de la tâche ou analyser l'identifiant du composant web. En thymeleaf, cela donne quelque chose comme : th:data-id et cela s'utilise avec element.dataset.id en javascript.
document.querySelectorAll('.task').forEach(item => {
item.addEventListener('click', event => {
// event.target est la tâche cliquée
}
});
Pour la dernière étape, le drag & drop, je vous conseille le lien suivant ;-) Attention, ce qui est déplacé est beaucoup plus fragile que des posts-its.